Why Data Centers In Space Are Doomed
The Unconventional Deployment Myths — Submerged, Orbital, and Other Expensive Distractions

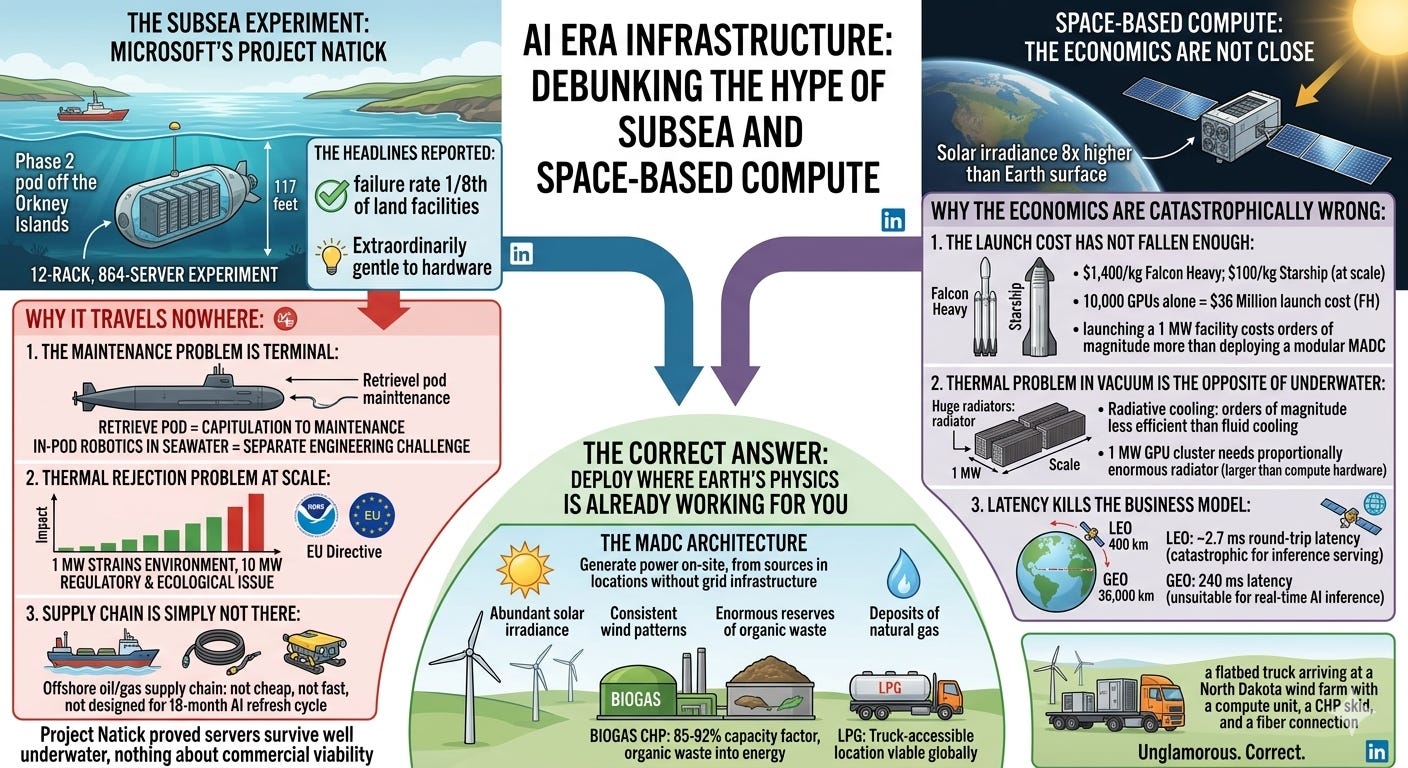
Every few years, someone publishes a breathless article about Microsoft’s Project Natick — the subsea data center experiment — as evidence that underwater compute is the future. Every few years, someone proposes space-based data centers as the solution to terrestrial infrastructure constraints. These ideas travel well on LinkedIn. They travel nowhere in the real world.
I want to be precise about why. Not dismissive — the engineering behind both concepts is genuinely interesting. But interesting engineering and viable infrastructure architecture are different things, and the AI era cannot afford to confuse them.

Project Natick: What Microsoft Actually Learned
In 2018, Microsoft deployed a 12-rack, 864-server data center pod in 117 feet of water off the Orkney Islands in Scotland. Project Natick Phase 2. They retrieved it in 2020. The results were published, celebrated, and then quietly filed away.
What the headlines reported: the failure rate of servers in the subsea pod was one-eighth that of servers in comparable land-based facilities. The submarine environment — stable temperature, no oxygen, no humidity — was extraordinarily gentle to server hardware.
What the headlines didn’t report: Microsoft has not built a single commercial subsea data center since 2020. The project remains an experiment. Not a product. Not a deployment model. An experiment.
There are reasons for this, and they are not resolvable with better engineering.
The Maintenance Problem Is Terminal
The failure rate of 1/8th for subsea servers sounds transformative until you ask: what happens when something does fail? In a land-based facility, a technician walks in and replaces the component. This takes minutes to hours. In a subsea pod, you have two options: send a submarine to retrieve the entire pod (Project Natick’s approach), or build in-pod robotic maintenance that can operate under 100+ meters of seawater.
Retrieving the pod is not a maintenance strategy. It’s a capitulation to maintenance — an admission that maintenance is so hard underwater that it’s easier to stop operations entirely, surface the entire facility, repair it on land, and redeploy. For a frontier AI training cluster running a multi-week training job on a $500 million model, “pause operations while we retrieve the pod” is not an acceptable SLA.
In-pod robotic maintenance under seawater is an entirely separate engineering challenge from in-pod robotic maintenance in air. The corrosion environment, the pressure environment, the communications environment — every variable that makes subsea hardware reliable also makes subsea maintenance uniquely difficult.
The Thermal Rejection Problem Gets Worse at Scale
Project Natick’s Phase 2 pod consumed approximately 240 kW of power. The seawater cooling worked beautifully at that scale. At 1 MW — the minimum unit for serious AI workloads — the thermal rejection requirements begin to strain the local oceanic environment. At 10 MW — the scale required for meaningful training clusters — the thermal footprint becomes a regulatory and ecological issue.
The U.S. National Oceanic and Atmospheric Administration (NOAA) regulates thermal pollution in U.S. waters. The European Marine Strategy Framework Directive imposes similar constraints. A 10 MW subsea data center rejecting waste heat continuously would require environmental assessment equivalent to a coastal power plant. The permitting timeline for that assessment: longer than building the same facility on land.
The Supply Chain Is Simply Not There
Building a subsea data center requires specialized pressure vessels, subsea power cables rated for the operational depth, subsea fiber optic connectors with appropriate pressure ratings, ROV support for deployment and retrieval operations, port facilities for assembly and maintenance, maritime insurance, and regulatory compliance across maritime law, telecommunications law, and environmental regulation simultaneously. The supply chain for all of this exists in the offshore oil and gas industry. It is not cheap, it is not fast, and it is not designed for the refresh cycles that AI hardware demands.
When the GPU generation changes every 18 months, you need to swap hardware every 18 months. In a subsea pod, every hardware refresh is a marine operation.
Project Natick proved that servers survive well underwater. It proved nothing about whether subsea data centers are commercially viable. These are different claims.
Space-Based Compute: The Economics Are Not Close
The case for space-based data centers typically runs: solar irradiance is 8x higher in orbit than on Earth’s surface, with no atmospheric absorption and no nighttime. You can capture enormous amounts of solar energy in space and beam it — or the compute results — back to Earth. No land footprint. No grid connection. No permitting.
The case is coherent as physics. As economics, it is catastrophically wrong.
The Launch Cost Has Not Fallen Enough
SpaceX’s Falcon Heavy, the current benchmark for heavy lift, carries approximately 63 metric tons to low Earth orbit at roughly $90 million per launch — about $1,400 per kilogram to LEO. A single NVIDIA H100 GPU module weighs approximately 2.6 kg. Racking 10,000 H100s requires roughly 26,000 kg of GPU hardware, not including structural support, power conditioning, cooling systems, network infrastructure, or the orbital platform itself.
At $1,400/kg, the launch cost alone for 10,000 GPUs is approximately $36 million. Before the GPUs themselves ($250,000 each at hyperscaler pricing = $2.5 billion). Before the platform. Before any system for transmitting data to and from Earth. Before any provision for the thermal management problem that becomes uniquely savage in the vacuum of space.
SpaceX’s Starship is expected to reduce costs to perhaps $100–200/kg at scale. Even at $100/kg, launching a 1 MW compute facility into orbit costs orders of magnitude more than deploying a modular MADC on a brownfield site.
The Thermal Problem in Vacuum Is the Opposite of Underwater
In a subsea data center, waste heat is efficiently conducted to the surrounding seawater. In space, there is no medium for convective or conductive heat transfer. The only mechanism for rejecting heat is radiation — and radiative cooling is orders of magnitude less efficient than fluid cooling at the temperatures involved in GPU operation.
A single NVIDIA H100 GPU operates at up to 700W thermal design power. In a vacuum environment, radiating that heat requires a radiator surface area proportional to the fourth power of the temperature differential. For a 1 MW compute cluster in orbit, the radiator array required would be physically larger than the compute hardware itself — a constraint that scales horrifically with cluster size.
The International Space Station uses a radiator array of approximately 2,500 square meters for a total thermal rejection requirement of roughly 70 kW. A 1 MW AI compute cluster would require a proportionally enormous radiator — one that exists in no current or planned orbital platform design.
Latency Kills the Business Model
Low Earth Orbit is approximately 400 km altitude. At the speed of light, the round-trip communication latency to LEO is approximately 2.7 milliseconds — one way. For inference serving (the dominant AI revenue use case), 2.7 ms of baseline latency added to every request is commercially catastrophic. For training workloads, the bandwidth requirements between compute nodes would require radio links that don’t exist.
Geostationary orbit (36,000 km altitude) is worse: 240 ms one-way latency. Fine for video calls. Unsuitable for real-time AI inference.
The Correct Answer: Deploy Where Earth’s Physics Is Already Working For You
The underwater and space proposals share a common failure mode: they try to solve the wrong problem. The actual problem is not that terrestrial locations are physically inadequate for data centers. It’s that terrestrial locations with grid infrastructure are economically and regulatorily constrained.
The MADC architecture solves the actual problem: by generating power on-site, from sources available in locations that don’t have grid infrastructure, it makes every location with accessible energy a potential compute site. No seawater required. No rocket required. No permitting for thermal pollution of marine environments or broadcast licenses for satellite communications.
Biogas CHP delivers 85–92% capacity factor, 24 hours a day, from organic waste that would otherwise emit methane into the atmosphere. Wind and solar, paired with battery storage and gas backup, deliver grid independence in coastal and plains geographies. LPG makes any truck-accessible location viable globally.
The physics of Earth’s surface — abundant solar irradiance, consistent wind patterns, enormous reserves of organic waste, deposits of natural gas — are already working in favor of distributed compute. The DDCU architecture simply uses them.
Underwater data centers are interesting science. Space compute is interesting science fiction. The actual future of AI infrastructure is a flatbed truck arriving at a North Dakota wind farm with a compute unit, a CHP skid, and a fiber connection.
Unglamorous. Correct.